RISCy Business
Table of Contents
from the December 1985 issue of Australian Personal Computer

The Reduced Instruction Set Processor (RISC) era has begun, albeit quietly, and working examples are now appearing on the market. Dick Pountain examines three such processors.
What exactly is a RISC, and why is it a good thing? A reduced instruction set processor, as the name suggests, is one which can execute only a small number of different instructions, compared to the prevailing standards of the day. In computing (as indeed in most walks of life) everything is a trade-off. A RISC processor trades off the number of instructions available to the programmer for speed; RISC processors can execute many times faster than their more complex brethren. When implemented as microprocessors in silicon, RISC designs also save precious space on the chip; smaller chips can be designed and debugged more quickly and cost less to fabricate.
The usual trade-off is code size. By having fewer instructions and fancy addressing modes, RISCs often require more bytes of code to do the same job. As memory continues to plummet in price, many people will come to find this an eminently sensible trade-off. And as I shall explain when discussing two other RISC systems (the Inmos Transputer and a machine based on the Forth language), the trade-off isn’t even inevitable.
As early as 1975, IBM began a research project on the 801 minicomputer which incorporated RISC ideas and is rumoured (remember this is IBM) to have been capable of 10 MIPS (million instructions per second), four times the speed of its 370 mainframe. The 801 research was spurred by studies of conventional computer architectures which suggested that the average processor spends most of its life executing a handful of simple instructions, mainly load, store, branch, add and subtract.
In the early 80’s, student projects at Stanford and Berkeley universities in California led to designs for reduced instruction set chips which achieved performances that surprised the industry as well as their creators. For instance, the second Berkeley chip, RISC II, with an 8MHz clock runs integer arithmetic C programs faster than a 12MHz 68000 does.
Despite these promising pointers, the computer industry has until now continued along its traditional path, which is to produce a new generation processor based on the old generation with more instructions added.
This drive for more and more instructions is not governed by any theoretical rationale. The original microprocessor instruction sets were designed in an ad hoc fashion by hardware engineers rather than programmers. They were in part copied from existing minicomputer designs such as Digital Equipment’s PDP-11 and the IBM 360, and in part were decided by the pure practicalities of what could be done with the technology of the day (remember that all those chips represented the state of the art of their time).
The RISC approach
A RISC processor is stripped down, like a racing car, for speed, speed and more speed. More speed lets us use more civilised tools to get the job done more quickly, more securely, and more reliably.
There is no single recipe for RISC processor design; the only thing which connects the three different approaches described in this article is that they all involve processors which can execute only a small number of instructions (from 40 to 70), and they can be implemented in a small amount of Silicon (tens, rather than hundreds, of thousands of devices). From that point they diverge completely, with stack-based versus register-based architectures, threaded versus block structured code, high-level versus assembler style instructions.
Most current microprocessor designs are ‘micro-coded’: that is, the processor instructions are written in a lower-level code called micro-code. Micro-code is fixed at design stage and cannot be accessed by programmers. Each processor instruction is implemented by a micro-program which controls the switching of gates, and the sequencing and routing of data around the chip needed to execute the processor instruction. The micro-code itself is executed by the control unit on the chip, almost like a computer within a computer. A sizeable part of the silicon area is devoted to a ROM which holds the micro-code sequences.
The most immediate advantage of a reduced instruction set is that it reduces this space required for micro-code ROM (in the ARM it is reduced to nil, as the instructions are hard-wired with no underlying micro-code level at all). This allows the size of the chip to be reduced and hence the lengths of the data paths, which in itself leads to increased speed.
One factor which all the designs discussed here share is a concentration on high throughput by efficient pipelining of instructions. The speed of a RISC comes from making as many of the instructions as possible execute in a single machine cycle, and guaranteeing that the processor rarely has to wait for the next instruction to be fetched. By using techniques such as packing more than one instruction into a word, and overlapping in time the instruction fetch, decoding and operand manipulation. The processor is kept working as fast as the silicon will allow all the time.
The so-called ‘Von Neumann bottleneck’ (that is, the limited speed with which a processor can access its memory), is attacked by every trick in the book, and occasionally by rewriting the book. One approach, exemplified in the Berkeley RISC, is to use the silicon space freed by the small instruction set to have lots of registers (up to 64) so that more operations can be performed without memory access. The Forth machine on the other hand uses stacks, implemented in ultra-high speed RAM, to achieve the same effect.
The ARM
The recently announced ARM (Acorn RISC Machine) chip, from the troubled manufacturer of the BBC micro, was a very well-kept secret indeed. A design team was set to work in the heady days before the company’s financial near-collapse of 1985, in collaboration with the US firm VLSI Technology Inc which supplied the CAD workstations and is fabricating the chips. The Acorn team had experience of VLSI design from working on the ULAs for the BBC Micro, but none in processor design. In a remarkable 18 months they designed the ARM from scratch and it worked as specified at the first attempt, although they would be the first to admit that this triumph is as much due to the RISC design philosophy as to their own unquestionable skills.
The ARM chip is a product of Acorn’s business division: it will certainly be incorporated into future computer products as well as sold to other manufacturers. So far, however, nothing specific has been announced, although the previously mentioned evaluation board which can be operated from a BBC Micro should be available soon.
The design team was inspired as much by the venerable 6502 as by other RISC researchers. Working with the 6502 on the BBC Micro had convinced them of the virtues of this simple design, both in execution speed and in its unrivalled response time to interrupts (better than that of present 16-bit chips).
The ARM design started, quite properly, with the instruction set rather than the hardware. In fact the whole design, debugging and proving of the chip was performed on_ software’ simulations (some running on BBC Micros with the 3MHz 6502 second processor) with no hardware prototype at all. The first chips were also the first hardware realisation of the project!
The ARM is closer to the Berkeley model of RISC than the other two systems discussed here. It uses 25 registers and a highly pipelined architecture to achieve a performance of 3 MIPS from a small (7mm square) chip. It contains 25,000 transistors. For comparison, the Motorola 68020 is 9mm square, contains 192,000 transistors and achieves about 2.5 MIPS. Clocked at the equivalent of 5MHz, ARM runs the APC Basic Benchmarks almost exactly 10 times faster than the IBM AT, and comfortably faster than the fastest machine in February’s list. Fabricated in a fairly conservative three-micron CMOS technology, it will be very much cheaper to manufacture than the 68000 series, and uses so little power that it doesn’t become even detectably warm in use.
ARM has 32-bit registers and data bus, plus a 26-bit address bus which enables it to address 64Mbytes of memory on byte boundaries. There are 25 registers in all, only 16 of which are normally available to the programmer (some extra ones become available during interrupts). The program counter is kept in register 15, and holds the status flags in its first six bits, there being no separate flags register.
All the instructions are 32-bit words (aligned on word boundaries), divided into several fields, and can be fetched in one cycle. All operations are performed on 32-bit quantities, the load and store instructions being smart enough to extract bytes and zero extend them to 32-bits when required.
There are 44 basic instruction codes, which can be categorised into five types: load/store single registers, load/store multiple registers, arithmetic and logical, branch, and software interrupts. No multiply or divide’ instructions are supported.
All instructions are conditional: that is, they include a test which has to be true for them to be executed. The first four bits of each opcode are used to select one of 16 possible conditions. The purpose of this is to reduce the number of branches required in a program, as branches reduce the efficiency of pipelining. When a branch is taken, the next (already fetched and decoded) instructions have to be thrown away, causing a break or ‘bubble’ in the pipeline.
There are only two addressing modes, base-relative and PC-relative. These are made highly flexible by permitting a second register, shifted if required by an on-chip barrel shifter, to be used as the offset. The result of the offset operation may be optionally rewritten to the base register and combined with the use of negative offsets; which gives the equivalent of the 68000’s pre and post auto-decrement and increment modes. The barrel shifter is also used for arithmetic and logic operations, and (without the programmer’s involvement) to align data words and to extract fields from instructions.
Branches use a 24-bit offset which allows branching anywhere in memory. There are no separate long and short jumps, and no reason to want them as they would save neither space nor time. Setting an optional link bit in the branch instructions copies register 15, the program counter, into register 14 so that jumps and subroutine call/returns are catered for by the same basic instruction.
All the ARM instructions can be executed in one clock tick, except for the load/store multiple register instructions which require one tick per register. These latter instructions provide a fast way of saving the processor state, and allow very efficient context switching for procedure calls in high-level languages and for interrupt servicing. To enable the ARM to be used in virtual memory systems, all the instructions are restartable when the Memory Manager orders an abort.
As an example of the way these simple instructions can be exploited, a number in a register could be multiplied by 17 by adding it to itself shifted left four times, in a single clock tick.
The control of data flow through this pathway is not performed by a single control unit as in conventional processors, but through a number of separate functional units. The instruction decoder, for instance, is a programmable logic array with the instructions all hardwired; there is no micro-code ROM, as bits in the actual instruction word provide most of the control information. Condition sequencer and instruction skip units allow a fetched, decoded instruction to be skipped if its condition fails, without breaking the pipeline of following instructions.
An instruction may be fetched from memory while its predecessor is being decoded and its predecessor is still finishing execution in the ALU. This state of affairs persists as long as register-to-register operations are being performed consecutively without branching, and it maximises the throughput of the processor. (All the arithmetic and logic instructions are register-to-register). The ARM’s maximum processor-to-memory bandwidth (the rate at which data can be transferred) has been measured as 18MHz, compared to 4MHz for the IBM AT, 2-4MHz for the Macintosh and 1.2MHz for the IBM PC. ARM has been designed to extract the most performance out of the cheap DRAMs currently used in personal computers, but could show even better performance with fast static memory parts.
The Inmos Transputer
The T414 Transputer, now coming off the fabrication lines after a delay due to process problems, is not usually thought of as a RISC machine. The Transputer is a radical design which can be used to construct parallel processing systems; it’s a ‘programmable component’ rather than a central processing unit. Systems built from large numbers of Transputers will be used for applications such as graphics, digital signal processing and control systems, which require extremely high computing performance. A recently announced project aims to build a super-computer from Transputers.
In order to facilitate the building of parallel processing networks, the Transputer contains a complete computer on a single chip. Each T414 chip has a processor, 2k of memory and four serial communications links on the same piece of silicon. The on-chip RAM (the next model, T424, will have 4k) enables each Transputer to perform local processing, as well as addressing extended off-chip memory if required. The four high-speed serial links enable the different Transputers in a network to communicate with one another at 10 Mbits/second. The performance of a single chip is the range from five to 10 MIPS, depending upon the program material being executed.
The T414 is a 32-bit device with 32-bit registers and a 32-bit address bus capable of addressing four gigabytes of off-chip memory. The name Transputer, Strictly speaking, refers to a family of designs, with different word sizes, numbers of links and built-in functions. Later, Inmos intends to produce 16-bit models (which save on silicon space and package pins), and devices with dedicated disk or graphics controllers on-chip.
Unlike the ARM, the Transputer is forced to use leading edge process technology. Simply fitting the components onto one chip requires packing densities not before attempted in commercial processors, and Inmos is using a sub twomicron CMOS process to achieve it: its experience in building high-performance RAM parts has been of valuable assistance. It is partly as aconsequence of this critical space shortage that the processor part of the Transputer has been designed as a RISC (although the designers are committed to it for ‘philosophical’ reasons too). Although the Transputer is a large chip with many devices on it, only 25 per cent of this space is available for the processor part.
The Transputer displays a very different RISC architecture from that used in the ARM. Instead of a lot of registers, it has virtually none. To be more precise, it has only six registers, and three of these are used as an expression evaluation stack. The other three are called the Workspace Pointer, the Instruction Pointer (that is, program counter) and the Operand Register, and none of them is used to hold data. In place of data registers, the Transputer employs its on-chip RAM to hold operands; the Workspace Pointer points to the area of RAM which is currently being used as the register set.
This feature was determined by the need for the Transputer to execute multiple concurrent processes. Switching contexts, when one process is suspended and another is started, can be achieved by switching the contents of the Workspace Pointer to point to the new process’s data area, and it is very efficient as few registers have to be saved. The on-chip static RAM is ultrafast, as it does not suffer the delays normally encountered in driving the pins to get signals off one chip and onto another. It can cycle as fast as the processor (2OMHz) so the overall effect is as if the processor had 500 32-bit registers, although of course they can hold either code or data.
The Transputer instruction set is designed to directly support the execution of a particular high-level language called Occam. Occam is a new language and the first to fully incorporate the concept of concurrent operations. It’s a block-structured language which superficially resembles Pascal or C. It would be bending the truth, but only very slightly, to say that the Transputer directly executes Occam code. Occam statements often compile into one, and always into very few Transputer instruc tions. For example, the Occam assignment statement:
x:= 1
compiles into the two instructions:
load constant 1
store local x
each of which executes in a single cycle.
The actual Transputer instruction set comprises around 60 instructions, which makes it indisputably a RISC machine. However, the Transputer is intended to be programmed only in Occam, never explicitly in machine code: Occam is its ‘assembly language’. The machine instructions are micro-coded rather than hard-wired like those on the ARM, the space taken up by ROM being compensated for by the small number of CPU registers needed.
There are no. special addressing modes. The majority of instructions are zero address, expecting to find their operands on the evaluation stack. The rest are one-address instructions which treat the whole of memory, including the on-chip RAM, as a continuous block. The first 16 locations in local (on-chip) memory are special cases which are addressed by single-byte instructions (for example, ‘store local’ previously mentioned). Array indexing and record addressing via pointers are performed by powerful single instructions rather than addressing modes. 32-bit multiply and divide instructions are provided.
Like ARM, the T414 Transputer uses a straight and uniform 32-bit data path which runs through all the registers and control blocks. It also pre-fetches instructions, but the pipelining is not quite so extended as in ARM due to the frequent process switches required when executing concurrent programs.
A very clever scheme of instruction encoding overcomes one of the disadvantages of RISC designs, namely the size of their machine code. All Transputer operation codes are one byte long (this also has the immediate benefit that on a 32-bit T414, four instructions are fetched at a time).
As eight bits are not enough to encode all the possible op-code/operand combinations, longer instructions may be built up by stringing together sequences. After analysing typical programs, a frequency encoding scheme has been devised whereby the most commonly used instructions are only one byte long, and the least commonly used ones are the longest. This leads to a code density which is higher than that of first-generation microprocessors, and much better than new processors like the 68000. For example, the two aforementioned instructions, load constant 1 and store local x, are both single-byte codes.
The scheme works as follows. Each byte-long op-code contains two four-bitfields, holding the function code and a data value:
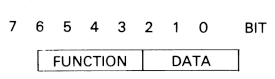
Four bits can only encode 16 functions, and 13 of these codes are used for the 13 most frequently needed instructions, including the arithmetic and logical operations, comparisons, and local load and stores. The other three function codes are used for the ‘prefix’ instructions, which say that the following ciperand consists of more than one byte, and the ‘operate’ instruction which does the same for instruction codes.
Prefixed instructions are built up in four-bit chunks in the Operand register by successive loading and shifting left. For example, the constant 897 hex would be loaded by:

which occupies three bytes and takes three cycles. This is not as time-inefficient as a naive first glance might suggest. Firstly, experience shows that the vast majority of constants used in programs are small integers like O and 1 (which would take one byte and one cycle). Secondly, the simplified instructions are so fast that you’re still winning anyway. A roughly equivalent Z80 instruction such as LD HL,#897 takes 10 cycles. As for it being verbose to program, let the Occam compiler worry about that.
A powerful consequence of this scheme is that any instruction can take an operand of any size up to the word size of the processor, and more importantly, the code becomes independent of the processor word size. The same code will execute on a 16-bit and a 32-bit Transputer.
In summary, although the Transputer is more than a RISC, the RISC philosophy was crucial in enabling its more ambitious features to be realised within the limits (just) of existing process technology.
Metaforth MF16LP
Metaforth is a start-up company founded by Dr Alan Winfield and Dr Rod Goodman. Alan Winfield is well known in the Forth community for writing one of the best tutorial books on the language, and for implementing Forth systems. Being an electronic engineer by training, Alan Winfield was not satisfied for long with purely software solutions, and set about designing a RISC computer to directly execute Forth code. The result, the MF16LP, is now starting manufacture.
Forth is at first sight an oddity among computer languages. It’s both compiled and interpreted, it uses an explicit stack for arithmetic, and it compiles threaded code which consists of lists of pointers rather than machine instructions. This curious structure makes immediate sense, though, when you stop regarding Forth as a high-level language and look upon it as the extendable instruction set of a hitherto non-existent ‘stack machine’. Existing Forth systems mimic this machine by implementing its instructions as subroutines written in the machine code of a host processor such as the Z80 or 68000.
Due to the overhead imposed by threaded code, and because the architectures of most microprocessors don’t fit very well with its virtual machine, Forth is not as efficient as it could be. Although Forth is many times faster than other interpreted interactive language systems like Basic and Logo, it is typically five to 10 times slower than a language like C, which compiles directly into the host processors machine code. Certain microprocessors such as the Motorola 6809 and the TI 9900 execute Forth much more efficiently than the Z80 or 6502 do, as their architectures ‘fit’ the Forth virtual machine slightly better.
The Metaforth machine is a direct hardware realisation of the Forth virtual machine. It’s a RISC processor which uses two dedicated hardware stacks instead of registers, and whose instruction set consists of the Forth primitive words, such as DUP, SWAP and DROP, from which other words are defined. It executes Forth much better than any conventional computer does, but due to the extreme simplicity of Forth’s underlying structure, it has turned out to be a quite extraordinarily fast computer architecture in absolute terms. The present version, which is still implemented in discrete logic rather than as a chip is capable of six MIPS. AVLSI implementation, combined with optimisations that Metaforth has already discovered, promises to push this up well beyond 10 MIPS.
The MF16 consists of a single-board computer (on a double Euro-card) built using Advanced Schottky TTL devices. The parameter and return stacks each consist of 2k of static RAM, which needs to have a 35-nanosecond (ns) access time as the machine’s cycle time is only 50ns. Main memory doesn’t need to be quite so fast, which would be an expensive proposition, but still needs to be 55-75ns if it is not to slow down the processor.
It’s amusing to see the reaction of engineers on first seeing the board, as their first question is always ‘Where’s the processor?’. Of course there is no microprocessor on the board, which looks for all the world like a RAM card. The whole processor requires about 20,000 transistors, which would make it avery small chip. AVLSI implementation is currently under design and will, like the ARM, be fabricated in the US.
The MF16 at present uses the customary 16-bit wide stacks with a 24-bit address bus. Consequently long address calculations must be done using double numbers; the VLSI version will go to full 32-bit stacks to avoid this.
The instruction set consists of a set of Forth primitives (chosen so that both the 79 and 83 standards can be accommodated) which are micro-coded. Part of the micro-code store is writeable: in other words, it is possible to add new machine instructions, and Metaforth intends to use this facility to customise the machine for special applications such as graphics and signal processing.
Extensive analysis has identified a set of 39 instructions which is sufficient to support a full Forth-79 or 83 system, but for efficiency reasons several other non-essential instructions are included to give a set of about 50 instructions. The great majority of these instructions can be executed in one instruction cycle.
The first prototype machine treated its instructions like conventional machine codes. A Forth assembler translated programs into streams of in-line op-codes, and the threaded nature of Forth had to be realised by CALL and RETURN instructions. However, Winfield discovered an ingenious scheme to implement threading directly into the hardware, with a zero-time overhead.
In very broad terms, the machine is split into two halves, one responsible for instruction fetch and the other for execution, each having its own stack. These halves can operate in parallel, so that the next threaded instruction can be ‘unravelled’ and fetched while the previous one is still using the parameter stack. This is the equivalent of the ARM’s pipeline, and combined with a unique dataflow ALU architecture contributes most of the speed.
The RISCy future
RISC processors have reached the point of commercial acceptance. IBM continues to work on RISC designs (it now has the 801 on a chip), and Hewlett-Packard is also deeply involved as are smaller companies.
For example, Pyramid is selling a fast Unix system which uses a custom RISC processor and Novix Corporation has produced a Forth chip designed by Chuck Moore, with similar capabilities to that of the Metaforth machine.
The lessons of RISC are that conventional processor designs have become counter-productively complex; that processor design is a job which requires the collaboration of software as well as hardware engineers; and that high-level languages can best be supported by simpler rather than more complex designs.
(Editor’s note: The RISC evaluation board for the BBC Micro, as described in this feature, is expected to be available from Barson Computers in January. It is claimed this will be the fastest microprocessor ever built.